I’ve spent many years working as a System Administrator and Support Engineer; the one thing I learned to value above anything else during those years was good logging. Good logging can make the difference between quickly finding an issue and spending hours debugging. Many of the more “formal” programming languages, such as Python, Java and C# have built-in, or easily importable, logging libraries that make it easy to create and standardise logs. However, when it comes to bash scripts, there are fewer tools available to help you craft and format log output. Yet many Sys Admins, DevOps Engineers and more use bash scripts every day to automate tasks, manage systems and more. Without good logs you’re fighting blind, or relying on the one guru in the office who just knows where to look. In this article I want to explore a few options and then share my opinionated view on what I think is a good approach to logging in bash scripts. I’ll even throw in a sample logging script that you can reference, or even import into your own scripts!
For those in a hurry, or who just want a solution, here are some quick links to the sections of this article:
- Want full, customisable, logging module you can use, for free, in your bash scripts? Jump to My gift to you - a logging module for bash
- Need a quick function to help with logging? Check out Logging functions - Starting our journey to a better way
Why log?
Before we dive into the how, let’s take a moment to consider the why. Why should you log output from your bash scripts? There are a few reasons:
- Debugging: When something goes wrong, logs can help you understand what happened and why. They can help you identify the root cause of an issue and fix it.
- Monitoring: Logs can help you monitor the health of your scripts. By looking at the logs, you can see how often the script is running, how long it takes to run, and whether it is producing any errors.
- Auditing: Logs can help you keep track of what your scripts are doing. By looking at the logs, you can see who ran the script, when they ran it, and what the script did.
- Compliance: In some cases, you may be required to keep logs of your scripts for compliance reasons. For example, if you are running a script that processes sensitive data, you may be required to keep logs of what the script did with that data.
Why do I care?
I’m sure many people reading this are probably saying “OK, sure, in some cases logging is important, but I’m just writing a simple script to do X, I don’t need to log anything”. And you may be right. If you are writing a simple script that you run once and then forget about, logging may not be necessary. However, if you are writing a script that you plan to run regularly, or that will be run by other people, logging can be very useful. I would also say that for any instance where someone other than you may run the script or need to review the logging you output, or if you have to come back to it yourself some time later, that spending some time considering how and what you log is extremely valuable.
There is one area where I think logging is particularly important, and that is adding timestamps to your logs. Consider these scenarios:
- Your script takes a long time to run, perhaps it exceeds some form of system timeout even. Without timestamps in your logs, or even logs at all (for those of you still not convinced) it becomes really hard to know where the script is spending its time. You likely resort to dumping
echostatements throughout the script to try and figure out where it’s getting stuck. With timestamps on your logs and a good logging strategy, you can quickly identify where the script is spending its time and why. - Your script produces an error. Maybe it collided with some other script or process; or maybe it’s a scheduled script and it fails at a certain interval for some reason. Without logs, and in particular without timestamps, it’s hard to really understand what happened, and drilling in to why it’s failing can take time and effort. With logs and timestamps, you can quickly identify things like does it always fail at a specific time, or the time it failed can help you correlate with other events on the system.
Another thing you should consider is the consistency, or standardisation of the format of your logs. We have great tools like grep and Select-String which can help us parse logs and industry tools like Splunk and Elasticsearch which can help us analyse logs. But these tools are only as good as the logs they are given. If your logs are inconsistent, or hard to parse, then these tools will be less effective. Consider, is the date before, or after the log level? Is the log level in square brackets, or round brackets? Is the script name included in the log message, or is it just the log level and message? These are all things that can make it harder to parse and analyse logs. Nevermind typos and variations like warn vs warning vs WARN vs WARNING, which is it that you are searching for? Can you be sure that you’ve found them all with a single grep?
For hints and tips on using regular expressions with grep and Select-String check out my article here.
Let’s be honest, other programming languages include logging for a reason. Whilst bash scripting is an extension of manual shell commands and is often seen as a quick and dirty get something done kind of language, it’s still a programming language and it’s still worth taking the time to craft good logs for anything that needs to be run more than once or by someone other than you.
I know many of my peers will push back and say that taking the time to craft good logs for “just a bash script” is a waste of time, that it’s hard to guarantee consistency and that it’s just not worth the effort. I disagree, as I’ve already said if others need to use your scripts or analyse the output then the value is there, but I do concede that it is hard to do right. Many of my scripts to date have had a variety of approaches and styles, so I’ve tried, failed, had success but with a lot of effort and otherwise been around the block on this one. So check out my gift to you at the end of this article for a logging module that I’ve put together and will be using going forward. I hope that it will help you to craft better logs with less effort.
The basics
Let’s start with the basics of what logging should look like, and what tools we have available to achieve this in bash scripts.
Understanding Log Levels
When implementing logging in your bash scripts, it’s important to understand the different log levels and when to use each one. Proper use of log levels helps filter noise and focus on what’s important depending on the context.
Common Log Levels
Here’s a breakdown of common log levels, from least to most severe:
-
DEBUG: Detailed information, typically valuable only for diagnosing problems. These messages contain information that’s most useful when troubleshooting and should include variables, state changes, and decision points.
[DEBUG] "Processing file: $filename with parameters: $params" -
INFO: Confirmation that things are working as expected. These messages track the normal flow of execution and significant events in your script.
[INFO] "Backup process started for database: $db_name" -
WARN: Indication that something unexpected happened, or that a problem might occur in the near future (e.g., filesystem running out of space). The script can continue running, but you should investigate.
[WARN] "Less than 10% disk space remaining on $mount_point" -
ERROR: Due to a more serious problem, the script couldn’t perform some function. This doesn’t necessarily mean the script will exit, but it indicates that an operation failed.
[ERROR] "Failed to connect to database after 3 attempts" -
FATAL: A severe error that will likely lead to the script aborting. Use this for critical failures that prevent the script from continuing execution.
[FATAL] "Required configuration file not found: $config_file"
When to Use Each Level
- Use DEBUG liberally during development but sparingly in production. It’s perfect for tracing execution flow and variable values.
- Use INFO to track normal operation milestones - script start/end, major function completions, or configuration loading.
- Use WARN when something unexpected happens but the script can recover or continue.
- Use ERROR when an operation fails but the script can still perform other tasks.
- Use FATAL only for critical failures that prevent the script from functioning at all.
With proper log levels, both you and others can quickly filter logs to the appropriate level of detail needed for the task at hand - whether that’s real-time monitoring (INFO/WARN/ERROR) or detailed troubleshooting (DEBUG).
Using echo
The most basic way to log output from a bash script is to use the echo command. This is a simple command that writes its arguments to standard output. For example:
echo "This is a log message"
Depending on your environment, this may, or may not actually end up in a log file. In the vast majority of cases, the output will not be written to a file and will only be visible on the terminal that ran the command or script. So, my advice is, assume that echo will not write to a file and that you need to do something else to capture the output.
And so…
Redirecting output to a file with >
If you want to write the output of a script to a file, you can use the > operator to redirect the output to a file. For example:
echo "This is a log message" > /path/to/logfile.log
This will write the output of the echo command to the file /path/to/logfile.log. If the file does not exist, it will be created. If the file does exist, it will be overwritten. This is standard redirection behaviour.
Note however that the output is fully redirected and will not be visible on the terminal that ran the command or script.
Redirecting output to a file with >>
If you want to append to a file, rather than overwrite it, you can use the >> operator. For example:
echo "This is a log message" >> /path/to/logfile.log
This will append the output of the echo command to the file /path/to/logfile.log. If the file does not exist, it will be created. If the file does exist, the output will be appended to the end of the file.
In most cases appending is the preferred method of logging as it allows you to keep a history of logs, rather than just the most recent output.
Note again that the output is fully redirected and will not be visible on the terminal that ran the command or script, in the same manner as the > operator. They are related after all…
So what if we want to both see the output on the terminal and write it to a file? Well, that’s where tee comes in…
Using tee to write to a file and standard output
If you want to write to a file AND standard output at the same time, you can use the tee command. For example:
echo "This is a log message" | tee /path/to/logfile.log
This will write the output of the echo command to the file /path/to/logfile.log and to standard output.
For many years this was my approach to adding some form of logging to my scripts. You can save yourself some time by making the log path a variable, like this:
LOGFILE="/path/to/logfile.log"
echo "This is a log message" | tee $LOGFILE
echo "This is another log message" | tee -a $LOGFILE
Some challenges
This is all great, but let’s take a step back and think about this in more depth. I said in Why do I care? that adding timestamps to your logs is important for example. We can do that using the date command, but now our echo commands are getting a bit more complex:
LOGFILE="/path/to/logfile.log"
echo "$(date) This is a log message" | tee -a $LOGFILE
echo "$(date) This is another log message" | tee -a $LOGFILE
Maybe when you do this you find that the output from date is not quite what you want and you want to format it differently. Sure, we can do that, but our “log lines” are really starting to grow now:
LOGFILE="/path/to/logfile.log"
echo "$(date +"%Y-%m-%d %H:%M:%S") This is a log message" | tee -a $LOGFILE
echo "$(date +"%Y-%m-%d %H:%M:%S") This is another log message" | tee -a $LOGFILE
Maybe we want to add other information to our logs, like the name of the script that is running, or whether it is an informational message or a warning or error. We can add this but our “log lines” are getting really long now:
LOGFILE="/path/to/logfile.log"
echo "$(date +"%Y-%m-%d %H:%M:%S") [INFO] [$(basename $0)] This is a log message" | tee -a $LOGFILE
echo "$(date +"%Y-%m-%d %H:%M:%S") [WARN] [$(basename $0)] This is another log message" | tee -a $LOGFILE
Here we also start to see where we can loose standardisation. Is it [WARN] or [WARNING]? Or [INFO] or [Info]? If you hand type every line, it’s easy to make a mistake, and if you copy paste maybe you forget to update the log line with the crucial piece of information that you need. I’ve done this myself countless times; “why is process X starting again?” only to go back through my script and find, “Oh, I copied the log line from process X and forgot to update it to now say process Y has started instead”.
What about using -x in my bash scripts?
The -x option can be a helpful tool in tracking what your script is doing and when. It will print each command that is executed to standard output before it is executed. For example:
#!/bin/bash
set -x
echo "This is a log message"
echo "This is another log message"
When you run this script, you will see the following output:
+ echo 'This is a log message'
This is a log message
+ echo 'This is another log message'
This is another log message
Now, I don’t know about you, but already I’m finding this a bit noisy, having every command printed out and then the output, it’s a bit much if you ask me. I absolutely agree that it can be helpful for debugging and then remove it for production, but it’s not a real logging solution. Try turning this on for a long script and then grepping through to find what happened, let alone what time it happened and I think you’ll agree that it’s not a great solution for logging.
For me, logging really should track what we need to know, when we need to know it and in a consistent format that we can easily parse and analyse. Often seeing every command is just too much noise and not enough signal. Your mileage may vary…
Logging functions - Starting our journey to a better way
OK, we have some tools to use and some challenges to overcome. Let’s accept that we want to be better than dozens of echo and tee commands in our scripts and start to think about how we can improve our logging. A more elegant approach is to define a dedicated logging function within your script. This function can take care of adding timestamps, script names, log levels, and anything else we want to add to our logs. Here’s an example of a simple logging function:
log() {
local log_level=$1 # A string representing the log level provided by the user when calling the function
local message=$2 # A string representing the message provided by the user when calling the function
local script_name=$(basename $0) # The name of the script that is running
local timestamp=$(date +"%Y-%m-%d %H:%M:%S") # The current date and time at the time the function is called
echo "$timestamp [$log_level] [$script_name] $message" | tee -a $LOGFILE
}
Now we can call this function to log messages in our script. For example:
LOGFILE="/path/to/logfile.log"
log "INFO" "This is a log message"
log "WARN" "This is another log message"
The output would look like this:
2021-10-01 12:00:00 [INFO] [script.sh] This is a log message
2021-10-01 12:00:01 [WARN] [script.sh] This is another log message
Immediately this is better. We only need to worry about the form of the log messages once. From then on out we can just call log with the log level and message that we want and the function does all the heavy lifting for us. If we want to make changes to the format of the log messages, we only need to change the log function, rather than every echo command in our script.
This is a great step forward if you ask me, and for a long time it’s been my go to solution. But here’s a challenge I came across that I want you to think about. You’re writing a script that is going to be used on a recurring scheduled task, during development and troubleshooting, you want to include extra logging, debug logging if you will, to help you understand what’s going on. But you don’t want to include this debug logging in production, it’s just too noisy and not needed. How do you handle this?
My solution was to have an environment variable, or more commonly a command line argument for -d or similar, that would indicate I wanted debug logging. This would be used to set a variable in the script that would then be used to determine if debug logging should be included. So far, so good. However to implement this you now need every debug log line to be wrapped in an if statement, like this:
if [ "$DEBUG" = "true" ]; then
log "DEBUG" "This is a debug message"
fi
Scale this across a moderately long script and you’re adding a lot of extra noise and processing to your script. You’re adding a lot of boilerplate code that obscures the productive lines of your script. Lots of extra logic that needs to be seen by a reader and acknowledged as not part of the main script logic. Now try coming back to your script 6 months later, or explain it to someone else as part of a knowledge transfer and it becomes hard. I know, I’ve done it. The conversation ends up something like “don’t worry about all these extra lines, they’re just for debug logging, you can ignore them.” This approach does work, and where nobody else is opening up your script or they understand the approach it does work well. But it’s not ideal.
So… what’s the solution? Well, I’ve been working on a logging module for bash scripts that I think solves this problem. It’s a bit more complex than the simple log function above, but it’s also more powerful and flexible, you can find it below.
What about logger?
Before we get to my solution, let’s take a moment to explore another tool we have called logger. logger is a command-line tool that allows you to send messages to the system log. This can be useful for logging messages from your bash scripts to the system log, which can then be viewed using tools like journalctl on Linux systems. For example:
logger "This is a log message"
We can then inspect the system log using journalctl:
journalctl | grep "This is a log message"
This can be a useful tool for logging messages from your bash scripts, especially if you want to centralise your logs in the system log. In many ways I think logger is a great tool. Personally I’m a fan of using the system log as it tightly integrates with everything else happening on a system. However, not everyone agrees and many engineers want, or expect, to find a dedicated log file for their script or application. If you want your logs somewhere other than the system log then you will need a custom logging solution such as the function above or the logging module I’ve put together, below.
Before we get to my custom solution though, let’s explore logger a bit more.
Using logger with log levels
logger also supports log levels, based on syslog levels. Here’s how you can use logger with different log levels:
-
DEBUG: Use the
-toption to specify the tag, and the-poption to specify the priority. For example:logger -t script.sh -p user.debug "This is a debug message" -
INFO: Use the
-toption to specify the tag, and the-poption to specify the priority. For example:logger -t script.sh -p user.info "This is an informational message" -
WARN: Use the
-toption to specify the tag, and the-poption to specify the priority. For example:logger -t script.sh -p user.warning "This is a warning message" -
ERROR: Use the
-toption to specify the tag, and the-poption to specify the priority. For example:logger -t script.sh -p user.err "This is an error message" -
FATAL: Use the
-toption to specify the tag, and the-poption to specify the priority. For example:logger -t script.sh -p user.crit "This is a critical message"
We can then inspect the journal log using journalctl for specific level(s):
journalctl -p user.debug
# Or multiple levels
journalctl -p user.debug -p user.info # Returns any log level from debug or info
journalctl -p warning..crit # Returns any log level from warning to critical
Tagging your logs
The examples above actually included something else, the -t flag which applies a tag to a log message. This can be useful for filtering logs from a specific script or application. For example:
logger -t script.sh -p user.info "This is an informational message"
You can then filter logs from this script using the tag:
journalctl -t script.sh
Tags and Levels together in the journal
Let’s put these two techniques together and see what it looks like
> logger -t demo -p user.debug "Hello World"
> journalctl -t demo
Mar 05 15:19:42 gw-fw13-01 demo[19621]: Hello World
> logger -t demo -p user.err "Goodbye Cruel World"
> journalctl -t demo
Mar 05 15:19:42 gw-fw13-01 demo[19621]: Hello World
Mar 05 15:20:40 gw-fw13-01 demo[20310]: Goodbye Cruel World
> journalctl -t demo -p err
Mar 05 15:20:40 gw-fw13-01 demo[20310]: Goodbye Cruel World
What my blog cannot easily show you is that on a modern shell with colour support you will see the log levels in different colours. This can be really helpful when scanning through logs to quickly identify the level of a log message. For example the error log level is often red. Try it for yourself and see.
My gift to you - a logging module for bash
OK! We’ve looked at logging using common console tools and we’ve talked about logger. It’s all a lot to remember isn’t it? So I’ve put together a logging module that is available on GitHub that you can use in your own scripts. You can find the module here including full documentation on how to use it and a series of demo scripts that showcase some of the use cases. I hope that you find it useful and that it helps you to craft better logs with less effort.
The module includes the following features:
- Simple functions for each logging level such as
log_info, andlog_errorwhich only require the message to be logged.- These functions make it immediately clear what the log level is and reduce the boilerplate code in your script.
- A
log_debugfunction that only logs messages if debug logging is enabled.- You can determine what level of logging you want to include in your logs, and only include debug messages when needed.
- It even provides an option to adjust logging level at runtime, so you can enable, or disable debug logging for a specific function or block without restarting your script.
- Colourised console output for different log levels.
- This makes it easier to see at a glance what level a log message is.
- Customisable log format.
- You can customise the format of your log messages to include whatever information you need.
- Customisable log file.
- You specify where you want the log, or if you want one at all.
- You can just use the module to log to console if you prefer and benefit from the colourised output without writing to a file.
- You specify where you want the log, or if you want one at all.
- Optional time zone support.
- You can specify whether logs should be UTC or your local time zone.
- Optionally send logs to the system log/journal as well
Getting started with the logging module
To get started you just need to download logging.sh from my provided GitHub repository and source it in your script. Here’s an example of how you might use it:
#!/bin/bash
# Source the logging module
source logging.sh
# Set the log file
LOGFILE="/path/to/logfile.log"
# Initialise the logging module
init_logger --log $LOGFILE --level INFO --utc # Will initialise the logger to write to the log file, with INFO level logging and in UTC
# Log some messages
log_info "This is an informational message"
log_warn "This is a warning message"
log_error "This is an error message"
log_debug "This is a debug message"
Note 1: The init_logger function should be called before any other logging functions are called to configure key options such as writing to log file or to the journal. It sets up the logger with the specified log file, log level, and time zone and other configurations.
Note 2: You do not need to locate logging.sh in the same directory as your script. You can place it anywhere you like and source it with the full path (using relative paths can sometimes generate unexpected behaviours).
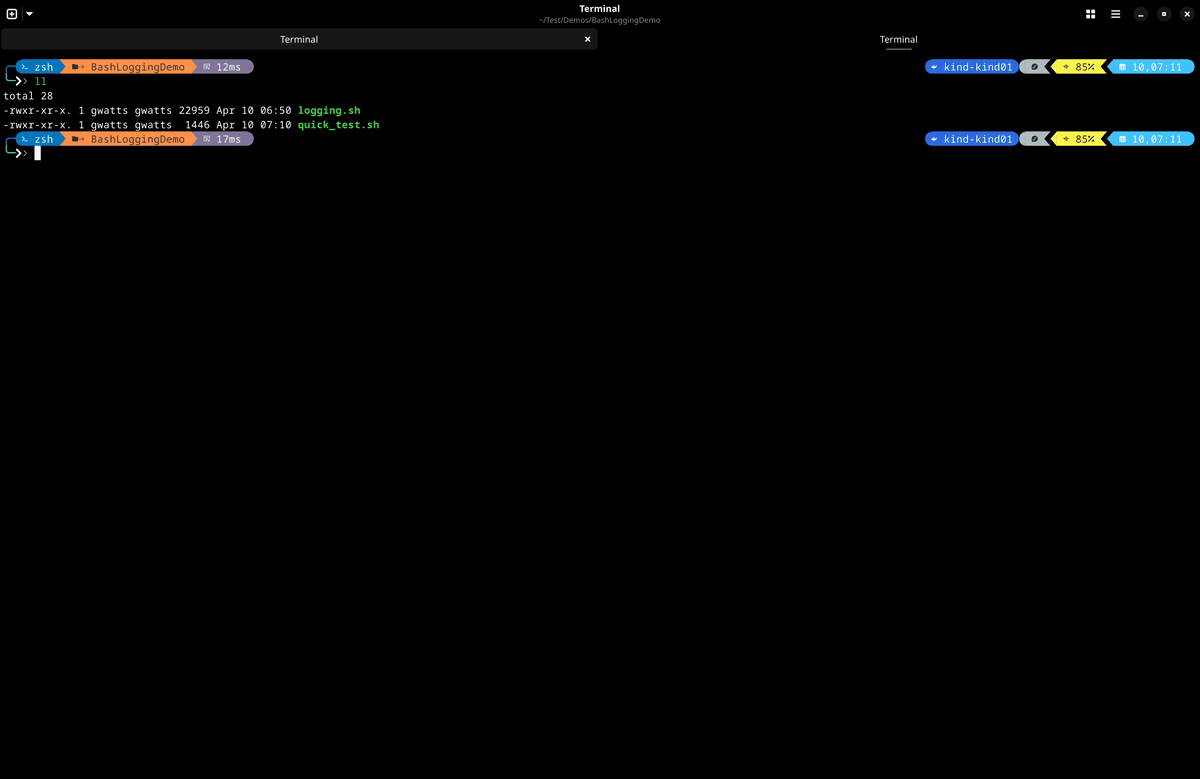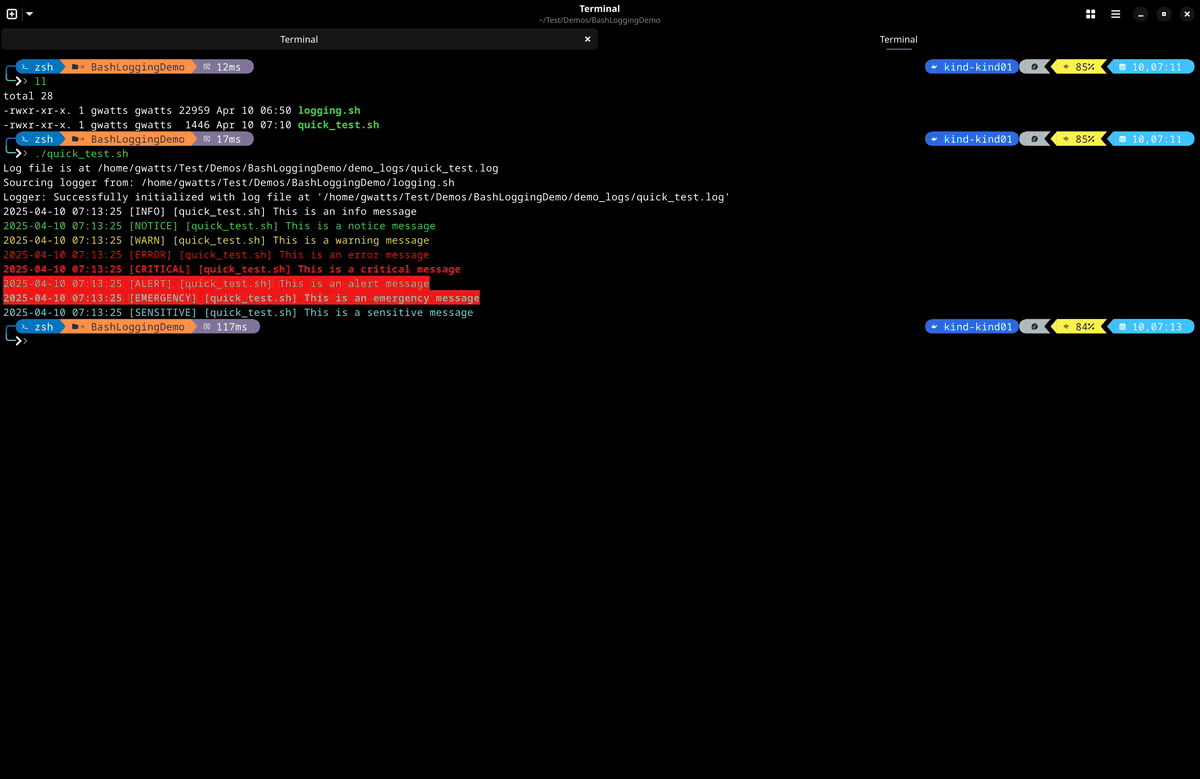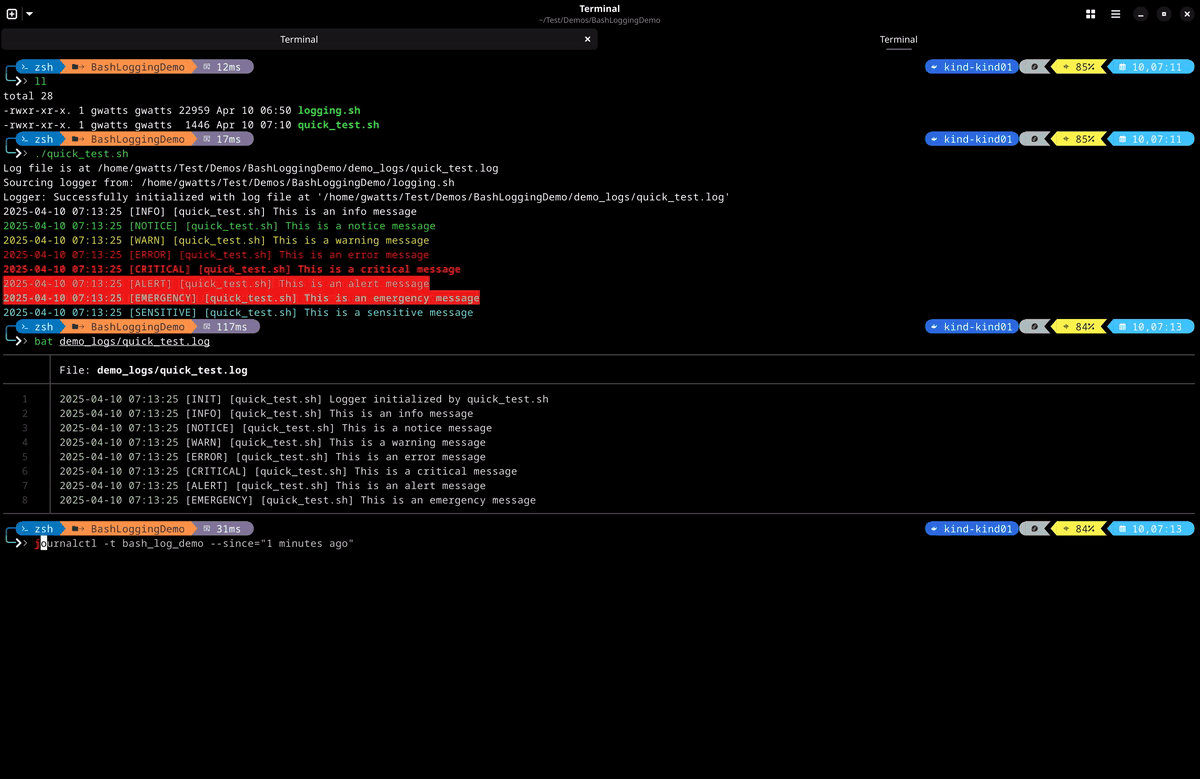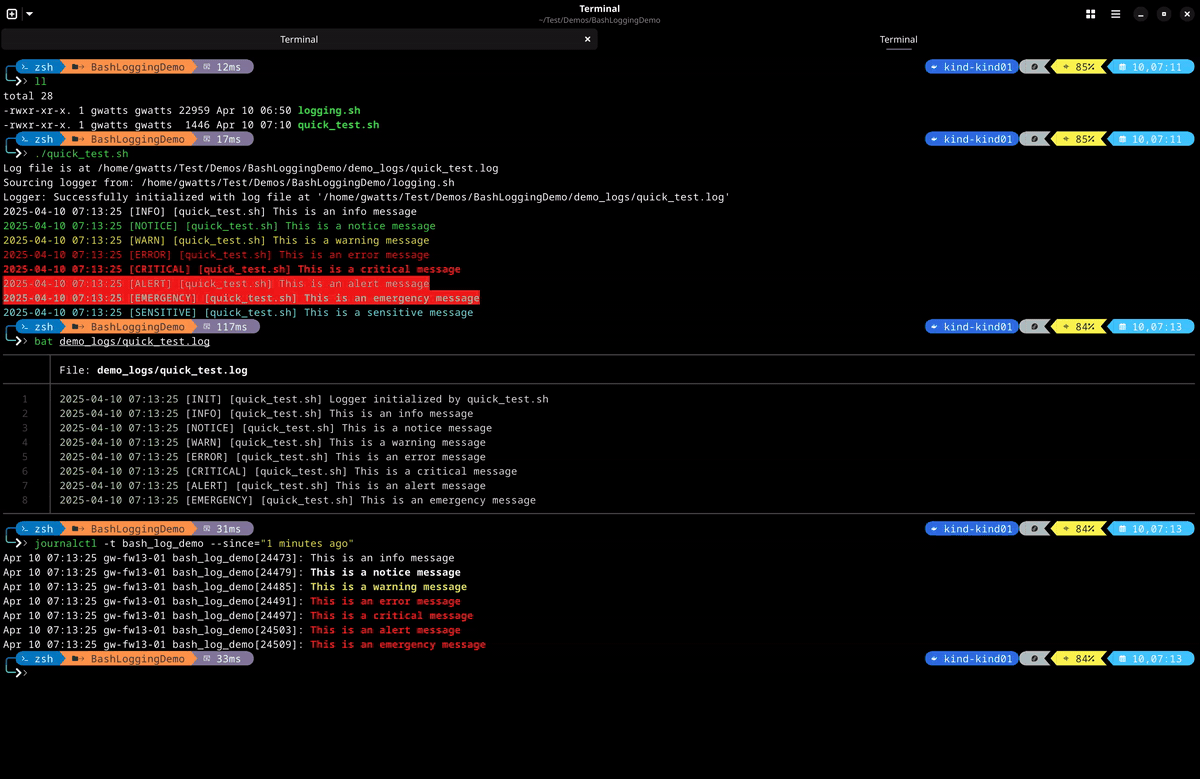
- This is a simple demo of the logging module in action. You can see that the log messages are colourised and include the log level, script name and timestamp. The log messages are also written to the specified log file and the journal.
Adding Debug support to your script
You’ve implemented the logging module and you’re now logging messages at different levels. But you want to add debug logging to your script, and you want to be able to enable or disable it at runtime. Here’s how you can do that:
- Add a
-dor--debugcommand line argument to your script. - Include a variable in your script for
LOG_LEVELthat is set toINFOby default. - If the
-dor--debugargument is provided, setLOG_LEVELtoDEBUG. - Call the
init_loggerfunction with theLOG_LEVELvariable, e.g.init_logger --log $LOGFILE --level $LOG_LEVEL.
Let’s see that in action:
#!/bin/bash
# Source the logging module
source logging.sh
# Set the log file
LOGFILE="/path/to/logfile.log"
# Set the log level
LOG_LEVEL="INFO"
# Check for debug flag
if [[ "$1" == "-d" || "$1" == "--debug" ]]; then
LOG_LEVEL="DEBUG"
fi
# Initialise the logging module
init_logger --log $LOGFILE --level $LOG_LEVEL
# Log some messages
log_info "This is an informational message"
log_warn "This is a warning message"
log_error "This is an error message"
log_debug "This is a debug message" # Only prints to console and/or log file if debug logging is enabled
Now you can run your script with the -d or --debug argument to enable debug logging. For example:
# Debug use
./script.sh --debug
# Normal use
./script.sh
That’s it! It’s as simple as that! You can now include debug logging in your script and enable or disable it at runtime. Obviously you can have a more complex argument setup for your script with getopts or similar depending on your needs, but this is a simple example to get you started.
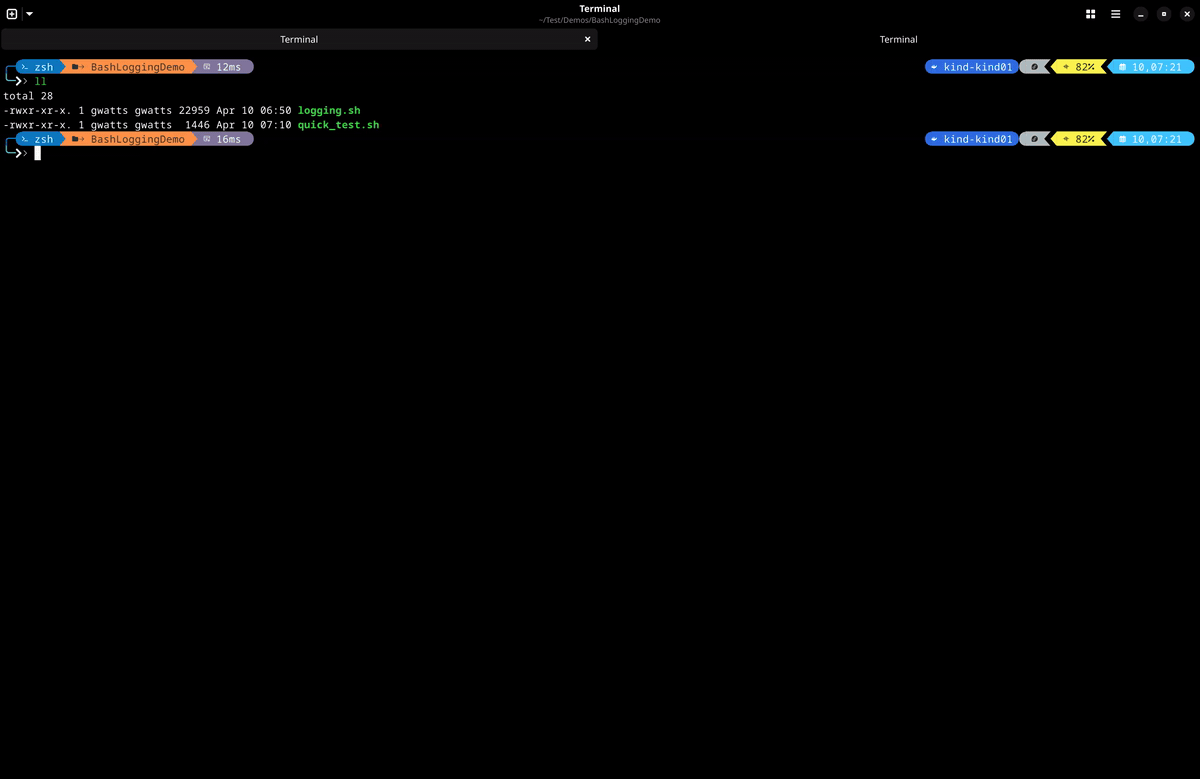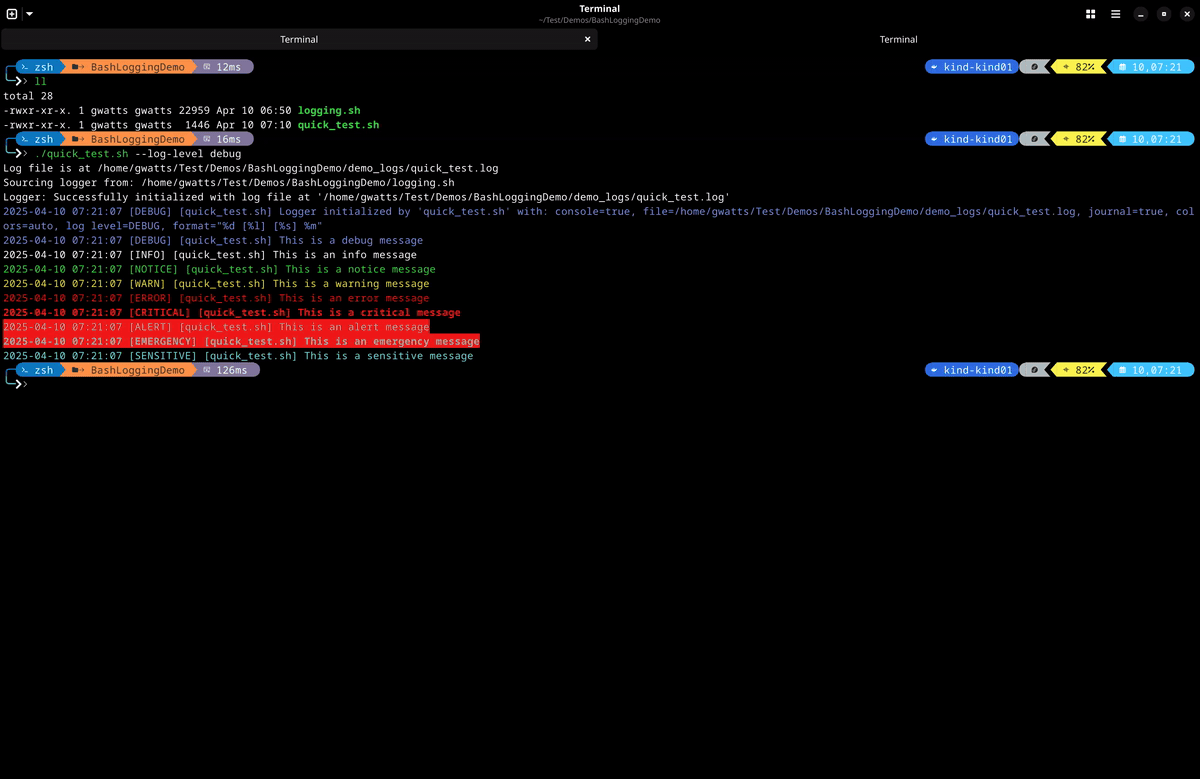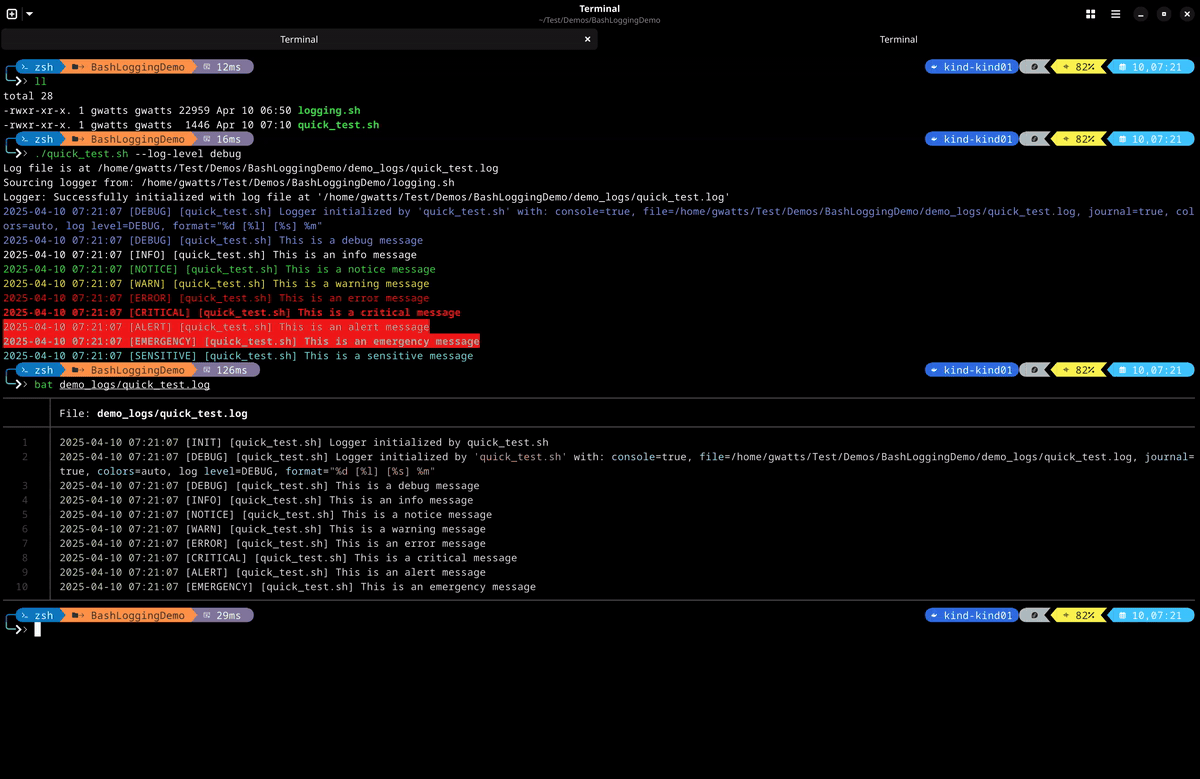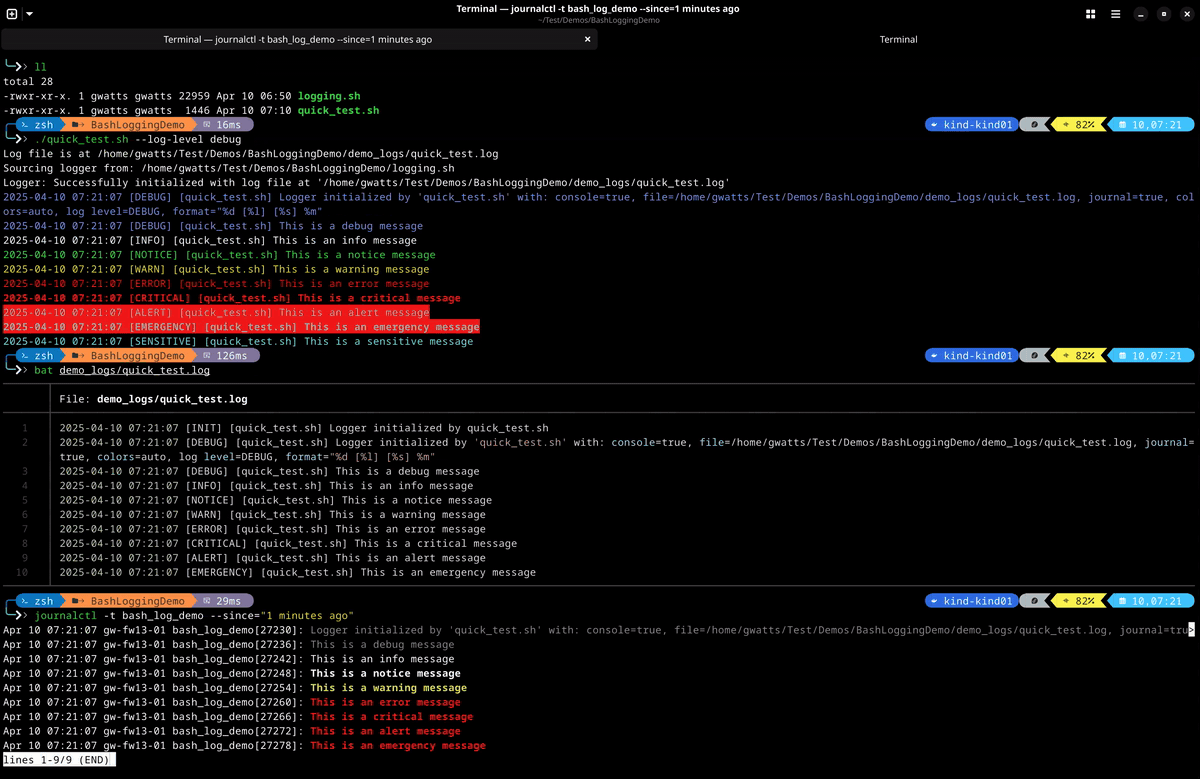
- This is a simple demo of the logging module in action with debug logging enabled. You can see that the debug log messages are colourised and include the log level, script name and timestamp. The log messages are also written to the specified log file and the journal.
What else should I think about?
There are a few other things you should consider when implementing logging in your bash scripts:
- Log content: What information do you need to include in your logs? Or, what information should you NOT include in your logs?
- Log rotation: If your log files get too large, they can become difficult to manage. Consider implementing log rotation to keep your log files at a manageable size.
- Log retention: How long do you need to keep your log files? Consider implementing a log retention policy to automatically delete old log files.
Log content
As with any logging, we should spend some time considering what information we need to include in our logs, and what information absolutely should not be included. Here are a few things to consider:
-
Sensitive information: Be careful not to include sensitive information or Personally Identifiable Information (PII) in your logs, such as passwords, API keys, or other credentials. If you need to log this information, consider obfuscating it or using a secure logging solution.
- If, for some reason, you need to verify sensitive information during debugging, consider options such as:
- Only sending the logs to a secure location with an very short retention policy
- Only logging sensitive information to the console and not to a file
- Ensure that your console session itself is not logging
- The provided logging module includes a
log_sensitivefunction that will only log to the console and not to a file
- Remember that logs can be read by anyone with access to the log files, so be careful what you include in your logs.
- If, for some reason, you need to verify sensitive information during debugging, consider options such as:
- Error messages: Be sure to include detailed error messages in your logs to help with troubleshooting. Include any error codes, stack traces, or other useful information that can help you identify the root cause of an issue.
-
Contextual information: Include any contextual information that can help you understand what’s happening in your script. This might include the script name, the function name, the line number, or any other information that can help you trace the flow of execution
- The provided logging module includes the script name but not the function name or line number. This is something you could add if you need it.
- Timestamps: Include timestamps in your logs to help you understand when events occurred. This can be useful for correlating events across different logs and understanding the sequence of events.
- Log levels: Include log levels in your logs to help you filter and categorise log messages. This can help you focus on what’s important and filter out what’s not.
Log rotation
Log rotation is the process of archiving old log files and creating new log files to keep the log files at a manageable size. There are many tools available to help with log rotation, such as logrotate on Linux systems. You can also implement log rotation in your bash scripts by checking the size of the log file and creating a new log file when it reaches a certain size. Here’s an example of how you might implement log rotation in your script:
#!/bin/bash
LOGFILE="/path/to/logfile.log"
# Check the size of the log file
log_size=$(du -h $LOGFILE | awk '{print $1}')
# If the log file is larger than 1MB, create a new log file
if [ ${log_size%?} -gt 1 ]; then
mv $LOGFILE $LOGFILE.$(date +"%Y%m%d%H%M%S").log
fi
# Initialise the logging module
init_logger --log $LOGFILE --level INFO
Alternatively you can configure logrotate to manage your log files for you. This is a more robust solution and is recommended for production systems.
Log retention
Log retention is the process of deleting old log files to free up disk space. You should consider how long you need to keep your log files and implement a log retention policy to automatically delete old log files, especially if you are working in secure or regulated environments. Also, good green engineering principles say that we should not consume ever more disk space with logs that are no longer needed. Here’s an example of how you might implement log retention in your script:
#!/bin/bash
LOGFILE="/path/to/logfile.log"
# Delete log files older than 30 days
find /path/to/logs -name "*.log" -mtime +30 -exec rm {} \;
This script will delete log files in the /path/to/logs directory that are older than 30 days. You can adjust the number of days as needed.
Alternatively you can configure logrotate (See above) to manage your log files for you. This is a more robust solution and is recommended for production systems.
Wrapping up
I hope that you found this article useful, and in particular I hope that you find the logging module that I’ve put together can help you to craft better logs with less effort. I’m passionate about providing engineers with more information to empower better decisions and quicker problem resolution. I believe that good logging is a key part of that, and I hope that this module can help you to achieve that.
If this article helped inspire you please consider sharing this article with your friends and colleagues, or let me know via LinkedIn or X / Twitter. If you have any ideas for further content you might like to see please let me know too.